
HANA -J
배열 / 검색알고리즘 /BigO/해시테이블 본문
> 알고리즘 문제 안풀려서 정리하는 개념들.. 😢 잘하고 싶다
위의 내용을 계속 기억하고 있자
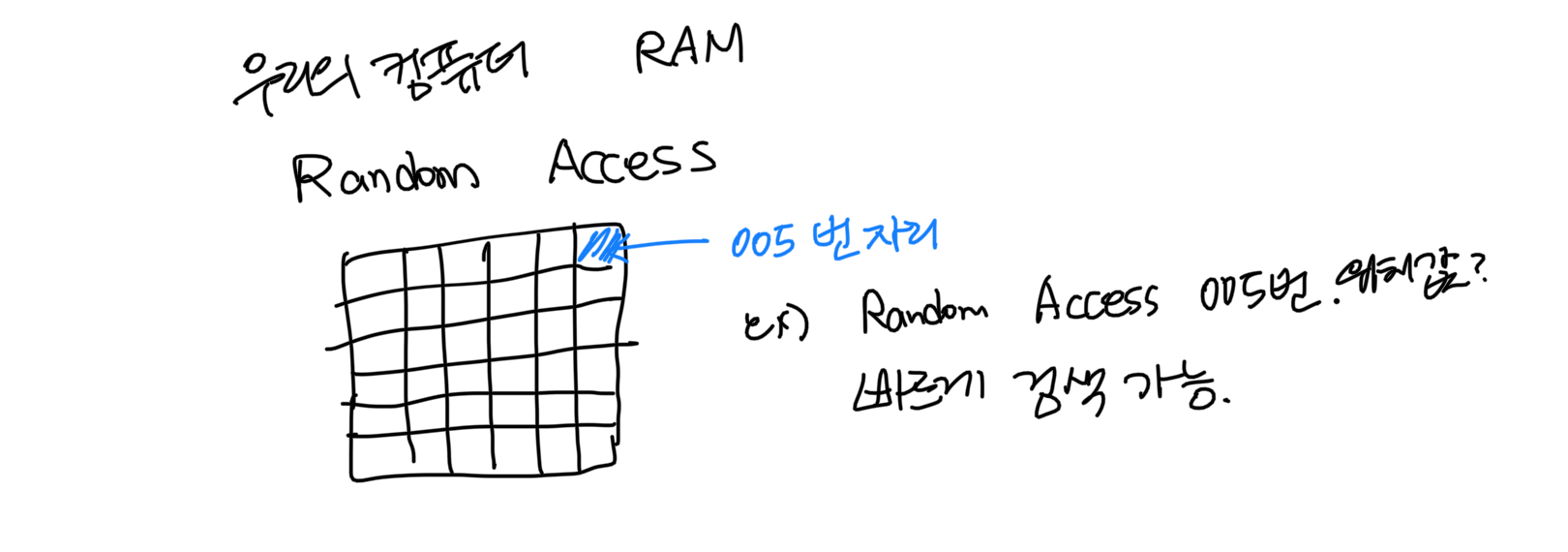
<Array>
1. Reading
컴퓨터는 배열의 길이를 기억한다 ! 배열의 길이와는 상관없이 인덱스에서 요소를 읽어내는 속도는 같다.
=> 많은 자료를 읽어와야 할 때는 배열이 짱이다.
2. Searching
배열이 어디서 시작하는지 알지만 특정 값의 위치는 모르기 때문에 하나하나 다 까봐야 한다.
=> 시간이 좀 걸린다.
3. Insert
배열 중간에 값을 삽입해야한다 ? 요소를 맨 뒤에서 부터 하나씩 하나씩 옮겨주어야 함
최악은 ?
배열은 미리 저장공간을 확보해 놓는다. 만약 배열의 크기를 넘어서 데이터를 저장해야하면 더큰 배열을 만들고 기존 값을 복사하고 삽입
4. Delete
삽입과 비슷하다 중간 값이 삭제 된다? 그럼 한칸씩 앞으로 옮겨주어야 한다.
<검색 알고리즘>
1. Linear Search
배열의 0번 인덱스 부터 순차적으로 검색 , 그래서 배열이 정렬되어 있지 않아도 괜츈하다.

2. Binary Search
이진탐색은 무조건 정렬된 배열만 가능. 물론 정렬이 되지 않은 배열에 데이터를 삽입하는게 더 빠름 그냥 맨 뒤에 넣으면 되니까..
데이터를 삽입하는거보다 데이터를 검색하는 일이 많다면 정렬된 배열을 사용하자!

데이터 인풋이 *2 => 검색 step은 +1
<Big O>

1. 배열의 크기에 상관없이 arr[0]을 읽는다면 시간 복잡도는 O(1) , 두번 읽는다고 O(2)아님 상수값은무시
=> big O는 상수값을 무시한다.
2. 이진탐색 시간 복잡도는 O(logN)
3. 선형탐색 시간 복잡도는 O(N)
4. 이중 for문등 지수시간이 걸리는 시간복잡도 O(n^2)
<해시 테이블>

=>위의 예처럼 글자수가 4개인 음식을 테이블 4번에 저장하지만 배열의 형태로 저장한다.
따라서 해시테이블의 시간복잡도가 항상 O(n)인건 아니다!
'개발 > 알고리즘' 카테고리의 다른 글
| 백준 [1011] - Fly me to the Alpha Centauri (node.js) (0) | 2021.12.23 |
|---|---|
| 백준[10250] ACM호텔(node.js) (0) | 2021.12.23 |
| 백준 [2869] 달팽이는 올라가고 싶다(node.js) (0) | 2021.12.21 |
| 프로그래머스 - 문자열 내 마음대로 정렬하기 (0) | 2021.11.27 |
| 프로그래머스 - 문자열 내림차순으로배치하기 (0) | 2021.11.25 |